Search K
Appearance
Dify 是一个用于开发 LLM 应用程序的开源平台,功能类似Cherry Studio。整合了工作流、RAG、Agent、模型管理、调用监控、API开放等功能,能够快速构建生产环境使用的业务处理流程。
本文主要演示在Dify中如何搭建一个智能的工作流,用于解决企业中的一些典型场景问题,例如智能客服、知识库查询、企业内智能OA调用,无论是标准化流程(如客服、审批)还是个性化需求(如行业定制模型),Dify 均能通过灵活的工作流设计与企业级安全架构灵活解决。
总而言之Dify功能非常强大,适用的领域也很广泛,产品经理不需要编写代码就可以实现很复杂的业务流程,团队效率大幅提升,而对于用户而言只需要自然语言就可以解决问题,也就是说只需要动动嘴皮子就能让Agent帮你完成所有的业务需求。开始之前需要了解几个基本概念。
MCP(模型上下文协议) 是一个开放协议,它规范了应用程序如何向 LLM 提供上下文。可以将 MCP 想象成 AI 应用程序的 USB-C 接口。
就像 USB-C 为设备连接各种外设和配件提供了标准化方式一样,MCP 为 AI 模型连接不同的数据源和工具提供了标准化方式,类似Call Function 以及 RPC 框架。
总而言之,Mcp 就是把Http接口按照统一的规范暴露给给模型,一般是一个SSE接口,让模型知道这个Mcp工具具备哪些能力,以便于当用户提问涉及到这类问题的时候模型可以自主调用Mcp接口进行解答,既然是统一的标准,那么不管使用什么语言进行开发都是可以的,只需要保证数据格式一致即可。
RAG(Retrieval-Augmented Generation,检索增强生成)是一种结合信息检索与生成式 AI的技术框架,核心目的是让大语言模型(LLM)在生成回答时,能够基于外部知识库的精准信息,而非仅依赖模型训练时的内部数据,从而提升输出内容的准确性、可靠性和针对性。
大语言模型(如 GPT、LLaMA 等)的局限性在于:
知识滞后:训练数据截止到特定时间(如 GPT-4 截止到 2023 年 4 月),无法覆盖最新信息(如 2024 年的政策、企业内部更新的文档)。
幻觉问题:当面对陌生领域或细节问题时,可能生成看似合理但错误的内容(“一本正经地胡说八道”)。
领域限制:通用模型对垂直领域(如医疗、法律、企业内部流程)的专业知识覆盖不足。
RAG 通过 “先检索、再生成” 的逻辑解决这些问题:
检索:从外部知识库(如企业文档、专业数据库、网页等)中精准找到与问题相关的信息片段。
增强:将检索到的信息作为 “上下文” 喂给大语言模型,让模型基于这些事实生成回答。
RAG 的技术流程:三步实现检索增强
一个完整的 RAG 系统通常包含数据准备、检索、生成三个核心环节,具体流程有以下几个步骤:
数据收集:整合企业内部文档(PDF、Word、Excel)、行业报告、网页内容、数据库记录等非结构化 / 结构化数据。
数据处理(清洗与拆分):
1、去除冗余信息(如广告、格式错误)。
2、将长文档拆分为 chunk(片段,通常几百字),避免因文本过长导致检索精度下降。例如,一本 500 页的产品手册可能被拆分为 1000 + 个片段。
Embedding):1、通过嵌入模型(如 OpenAI 的 Ada、开源的 BERT、Sentence-BERT)将每个文本片段转换为向量(Vector)—— 一种能表示文本语义的数字序列。
2、向量的核心作用是:将 “语义相似” 的文本映射到向量空间的 “邻近区域”(例如,“如何申请退款” 和 “退款流程是什么” 的向量会非常接近)。
3、向量存储:将所有文本片段的向量存入向量数据库(如 Pinecone、Milvus、FAISS),方便后续快速检索。
例:企业将 2024 年新员工手册拆分为 100 个片段,每个片段转换为 768 维向量,存入向量数据库。
当用户输入问题(如 “新员工试用期多久?”)时:
1、问题向量化:用与知识库相同的嵌入模型,将用户问题转换为向量。
2、相似性检索:向量数据库计算 “问题向量” 与 “知识库中所有片段向量” 的相似度,返回最相关的 Top N 个片段(通常 3-5 个)。例如,用户问 “试用期”,系统会从员工手册片段中找到包含 “试用期时长”“试用期考核” 等内容的片段。
3、过滤与排序(ReRank):可选步骤,通过关键词匹配、权限过滤(如敏感文档仅特定人可见)等进一步优化结果。
构建提示词(Prompt):将用户问题、检索到的相关片段(上下文)组合成提示词,例如: “根据以下信息回答问题:
1、【上下文 1】新员工试用期为 3 个月,特殊岗位可延长至 6 个月。
2、【上下文 2】试用期内累计迟到 3 次以上,公司有权终止合同。
问题:新员工试用期多久?” 模型生成:大语言模型基于上述提示词,生成既符合问题需求、又严格依据上下文的回答(如 “新员工试用期一般为 3 个月,特殊岗位可延长至 6 个月”)。
消除知识滞后:通过实时更新知识库(如新增 2024 年政策文档),让模型能回答最新问题(如 “2024 年个税专项附加扣除有何变化?”)。
减少 “幻觉”:回答严格基于检索到的事实,避免模型编造信息(尤其在法律、医疗等严谨领域)。
个性化与领域适配:企业可将内部数据(如产品手册、客户案例)接入 RAG,让模型成为 “企业专属助手”(如客服机器人基于内部产品信息回答用户咨询)。
可解释性增强:生成回答时可附带 “信息来源”(如 “答案来自《2024 员工手册》第 5 章”),提升可信度。
企业知识库问答:员工查询内部流程(如 “报销步骤”)、产品参数(如 “某型号设备功率”)。
智能客服:基于企业产品手册、售后政策,精准回答用户问题(如 “如何退换货”)。
法律 / 医疗辅助:律师检索案例库生成法律意见,医生参考病历和文献给出诊断建议。
垂直领域搜索:如学术论文检索(基于用户问题返回相关论文片段并总结)、新闻资讯聚合。
好了,前面已经了解到了MCP和RAG,学习一项新东西的时候最好带着清晰的目的去学习,这样才能提升效率。
接下来我们使用(工作流+MCP+RAG)来实现一个具体的需求,需求如下:当用户想查询天气的时候模型自动调用查询天气的MCP获取信息,而当用户咨询产品信息相关的时候则从知识库进行检索,通过模型总结后返回答案。
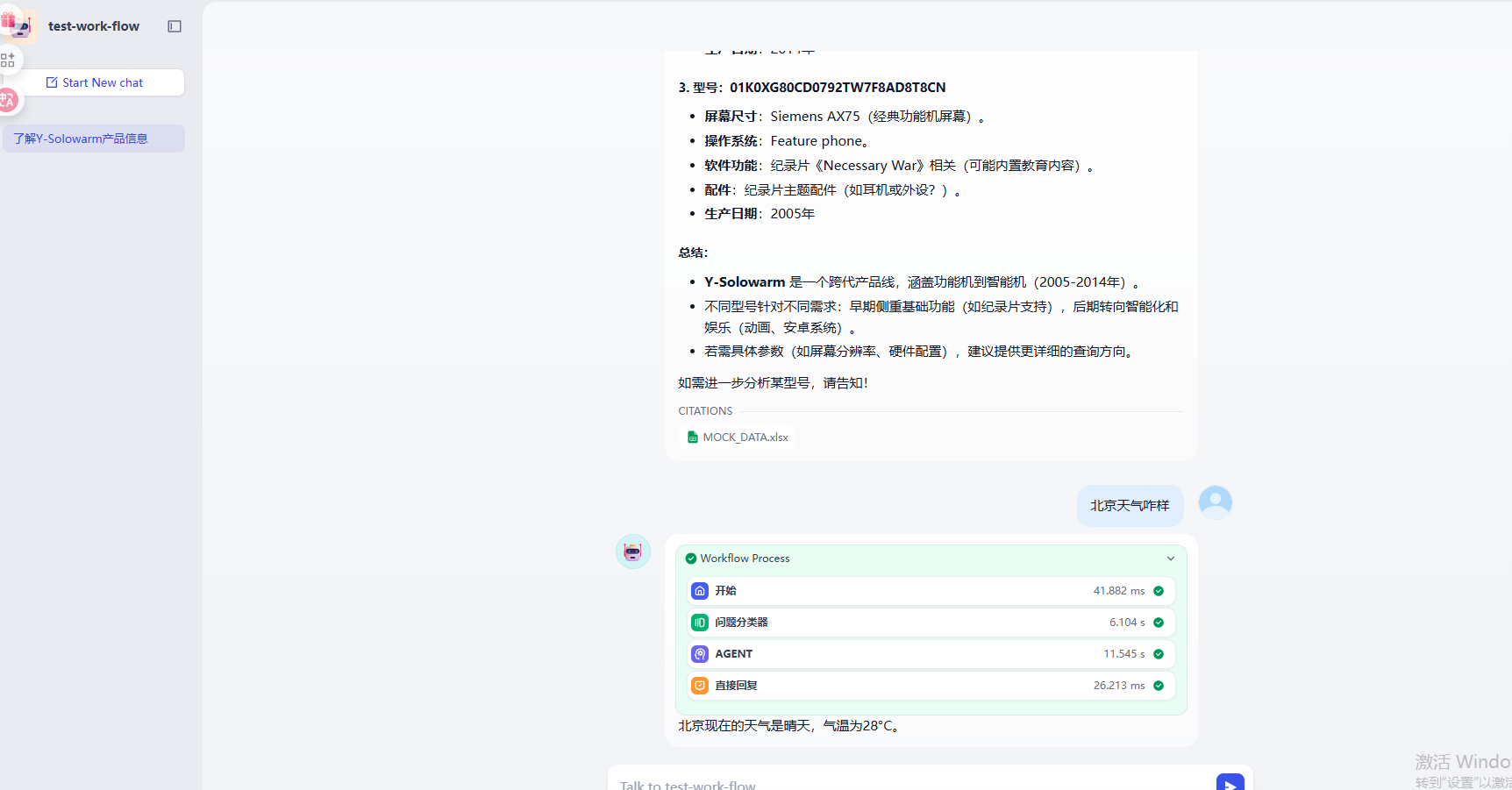
可以先看一下最终需求的实现效果,当我们咨询产品信息的时候工作流会自动调用知识库检索
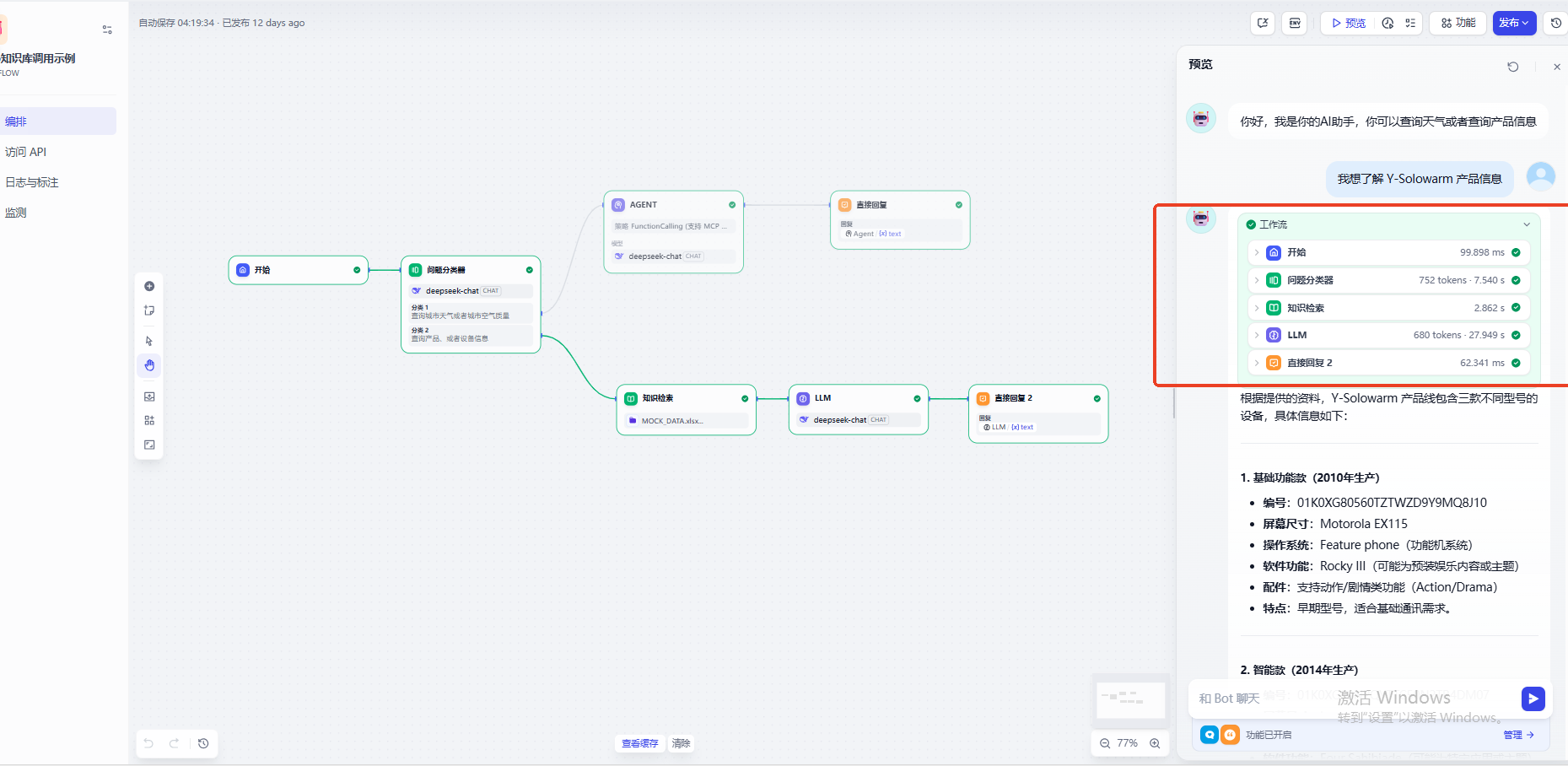
而当我们查询天气相关问题的时候,工作流Agent会自动调用MCP接口给用户回复
点击Dify上方的知识库菜单
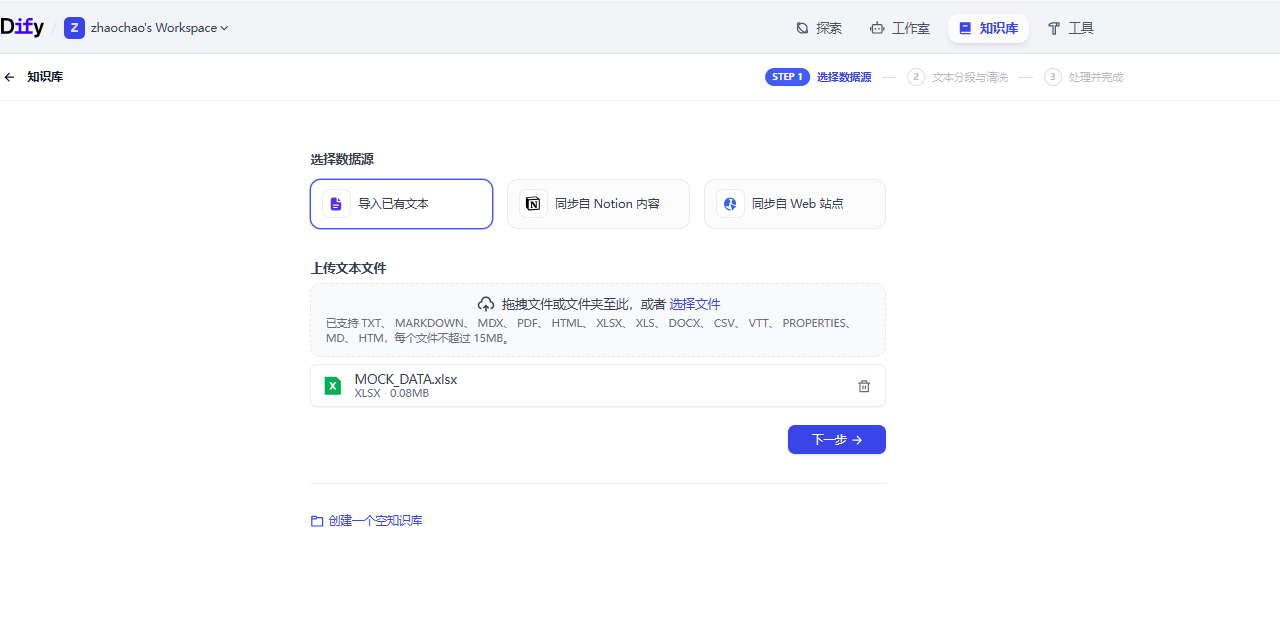
接下来需要使用模型对知识库嵌入处理,这里索引方式推荐使用高质量,通过指定的嵌入模型去处理文档效果更好,自带的经济模式效率很低。
这里我使用的是硅基流动平台订阅的免费Embedding模型,点击预览块我们可以检查一下知识块是否完整,假设文档里面字符最多的记录可能是900,那么我们分段长度应该设置超过900,例如1024,才能保证检索出来的Chunk完整性。
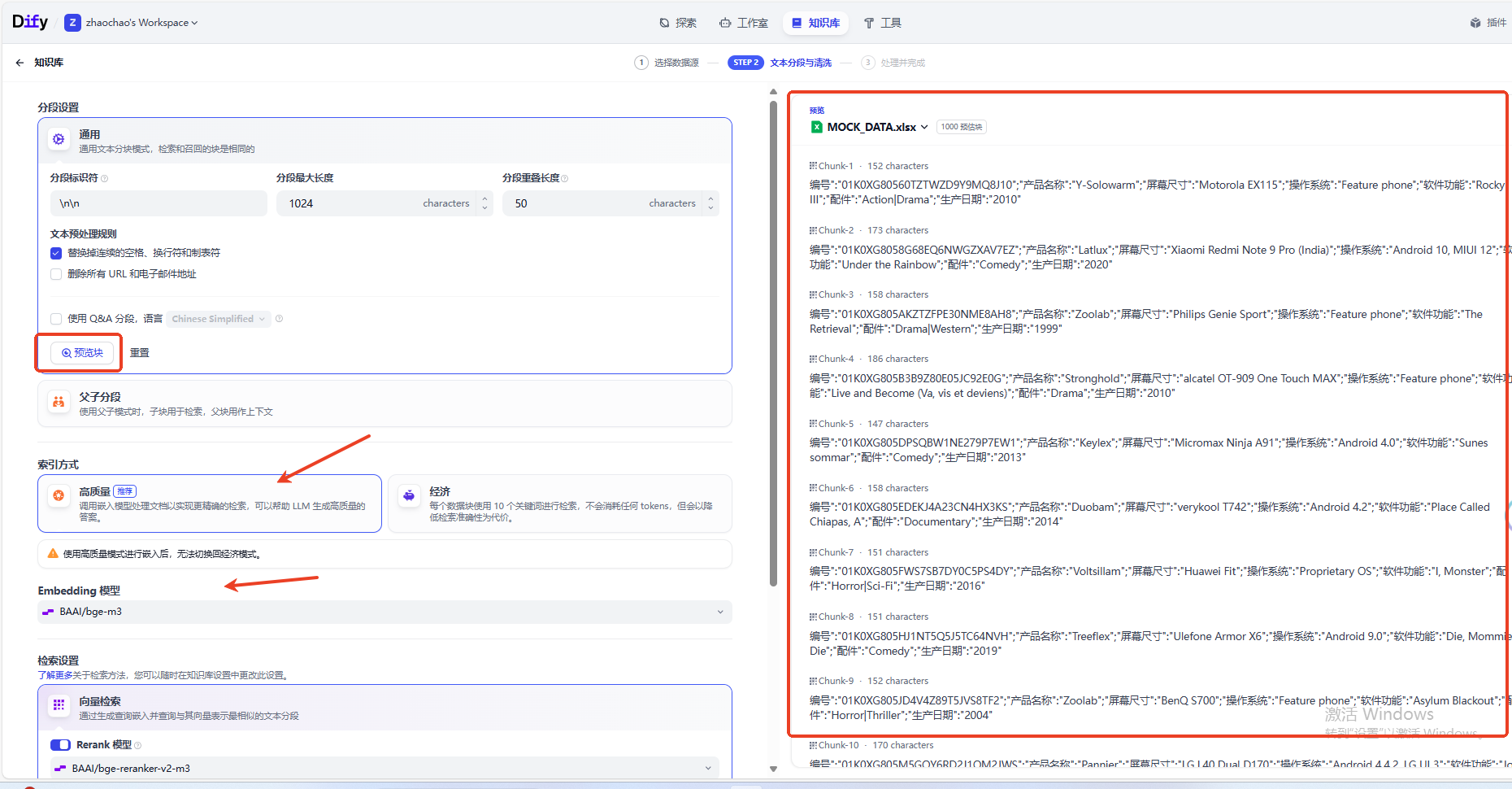
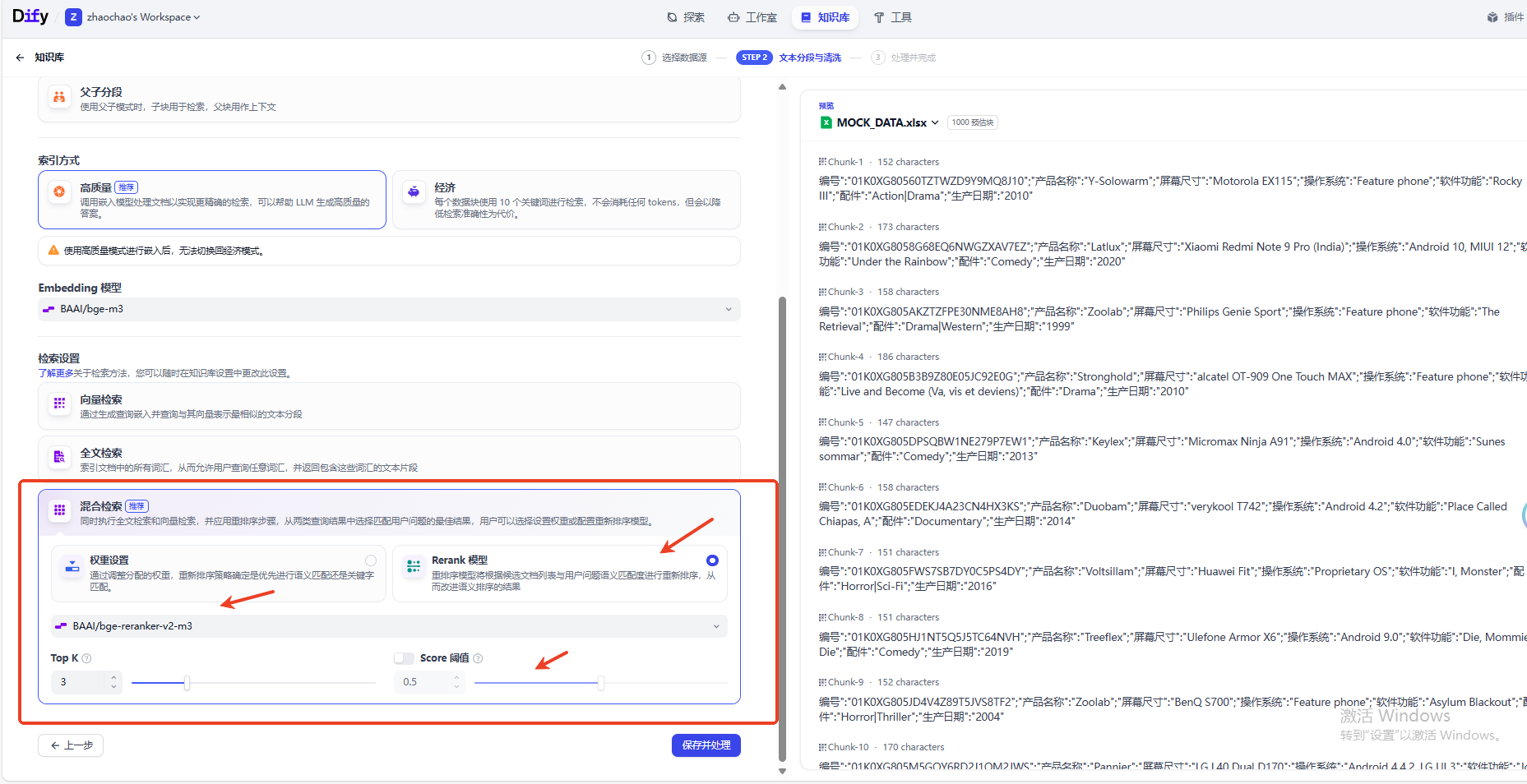
接下来需要进行检索设置,这里推荐混合检索,同时执行全文检索和向量检索,并应用重排序步骤,从两类查询结果中选择匹配用户问题的最佳结果,用户可以选择设置权重或配置重新排序模型。
这里使用与嵌入模型想相同的重排模型,也是硅基流动订阅的免费重排模型,可以设置Score < 0.5的直接舍去。
创建完成后只需要等待知识库索引完成,就可以使用了
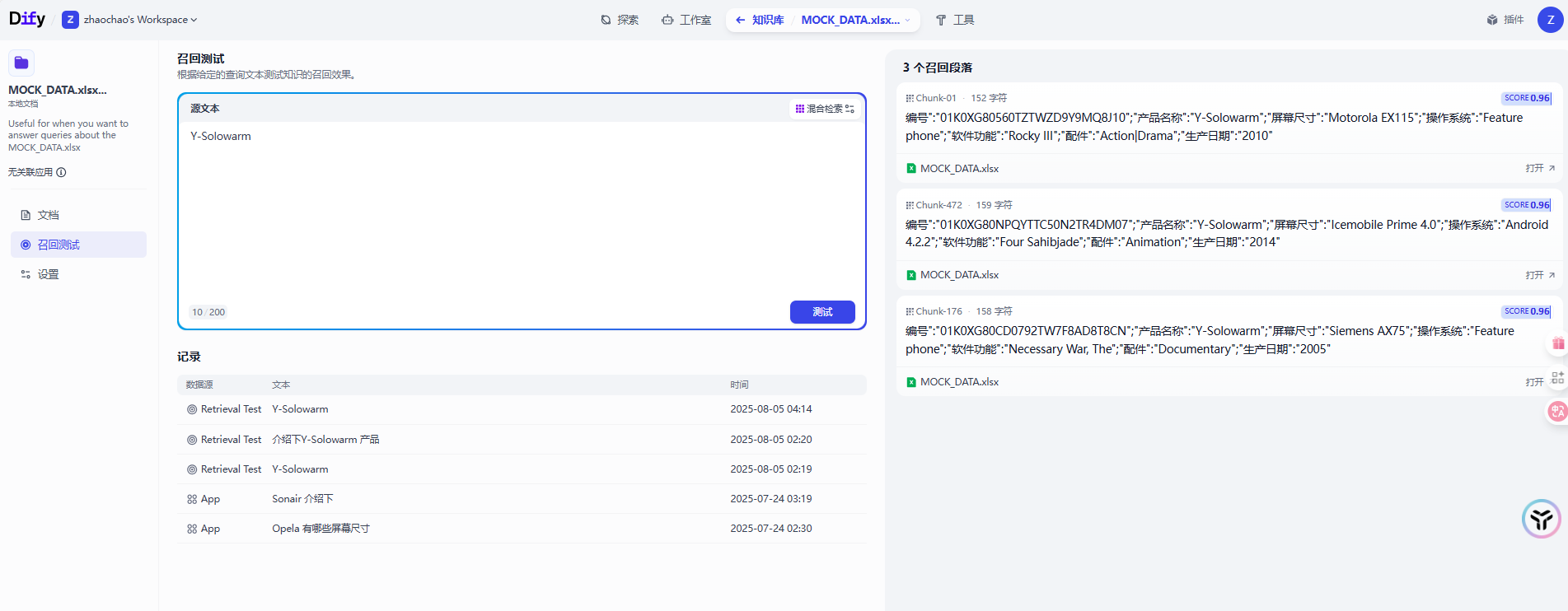
文档处理完成后我们可以在召回测试这里测试一下知识库检索的效果,可以看到这里的检索效果还是比较理想的
需要提前准备一个MCP接口,步骤可以参考前面的文章, Spring AI快速创建MCP服务
需求的实现方式有很多种,这里使用的是CHATFLOW,可以立即为带记忆能力的工作流,本质还是工作流
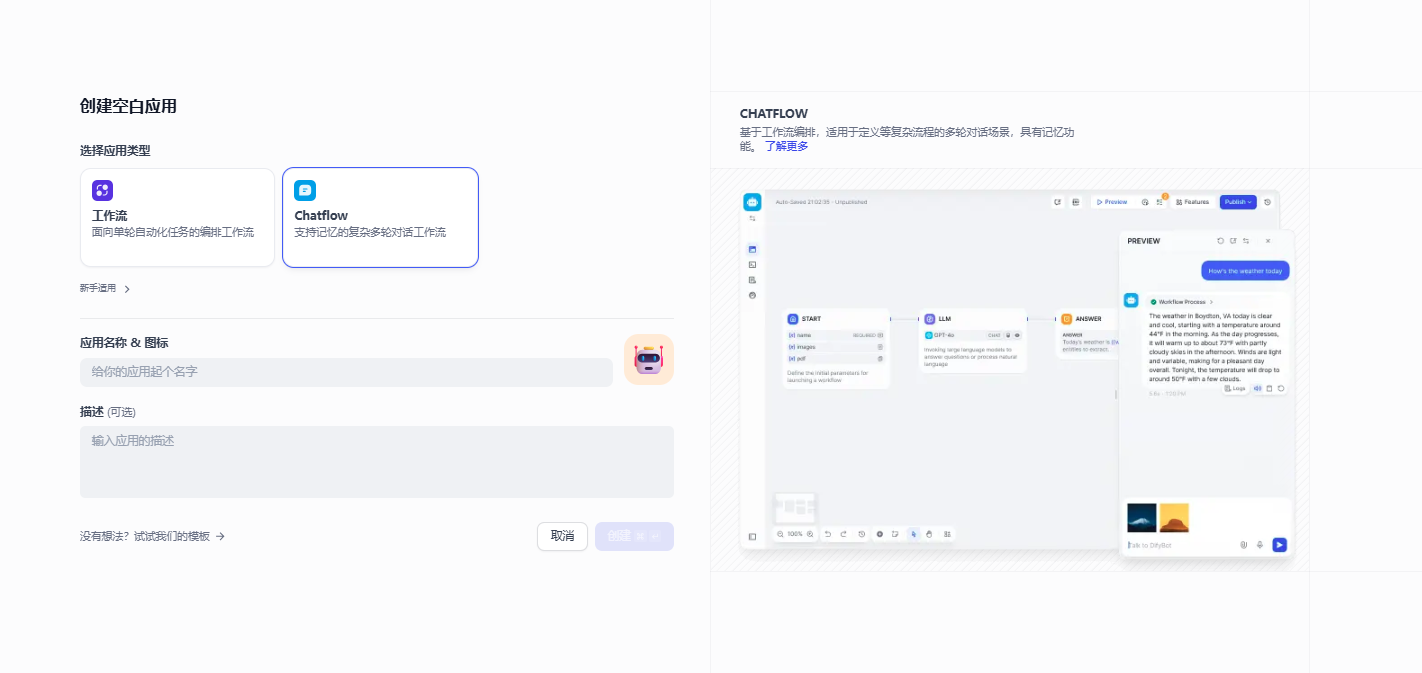
首席按可以使用问题分类器进行用户问题分类,使用的是deepseek模型
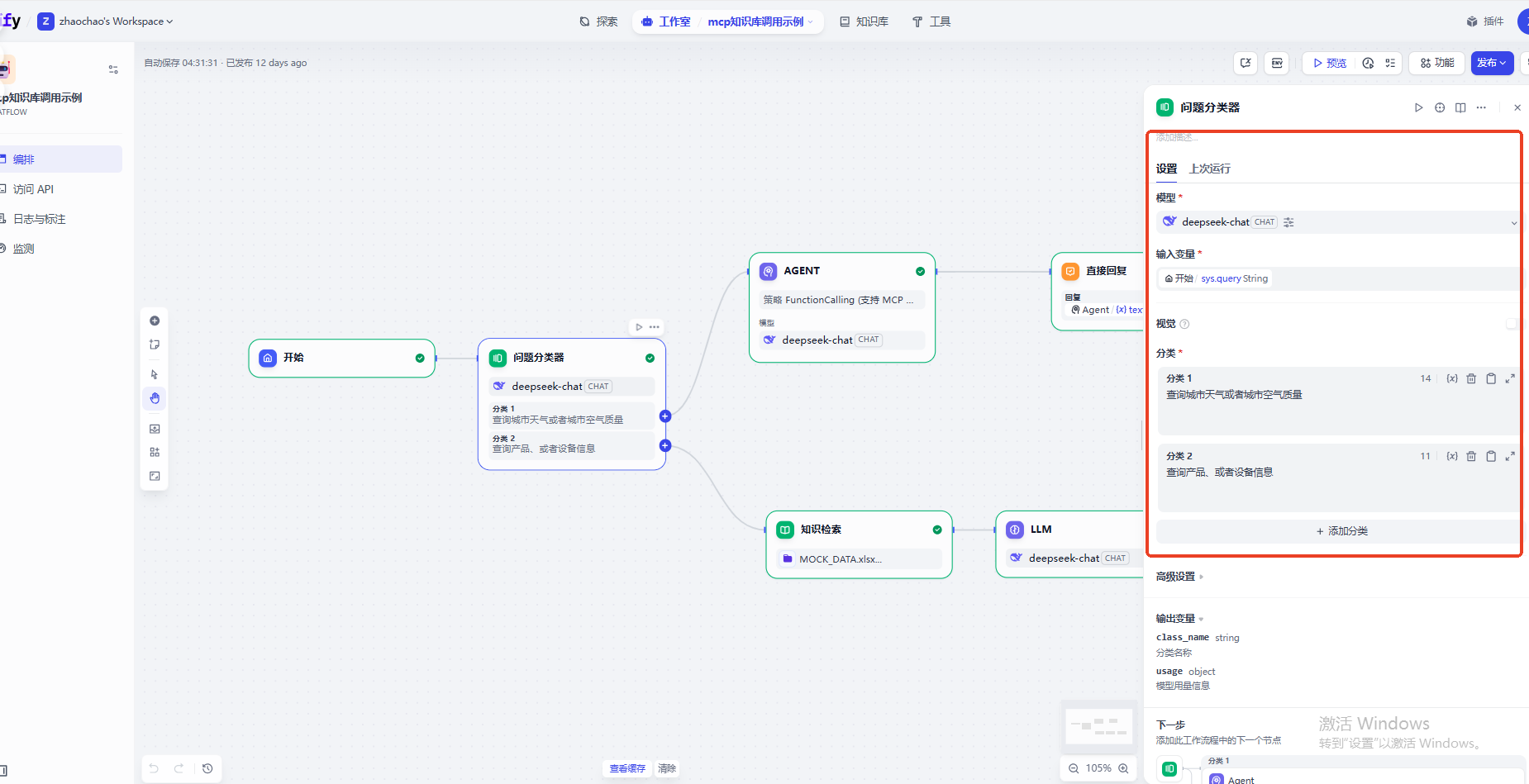
直接使用知识库检索工具,指定知识库,指定查询变量
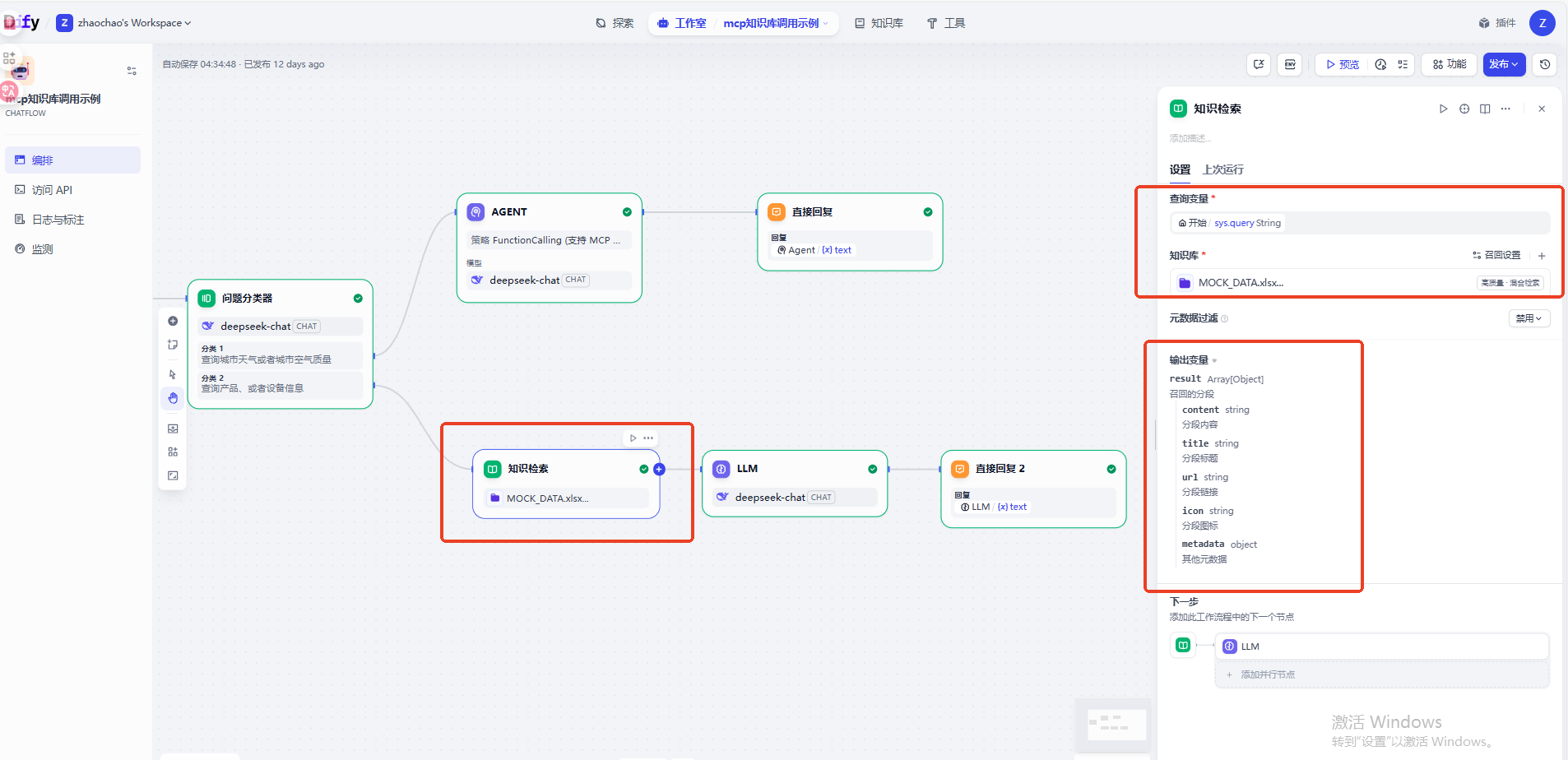
知识库检索结果是结构化的数据,我们直接丢给模型进行总结然后输出自然语言
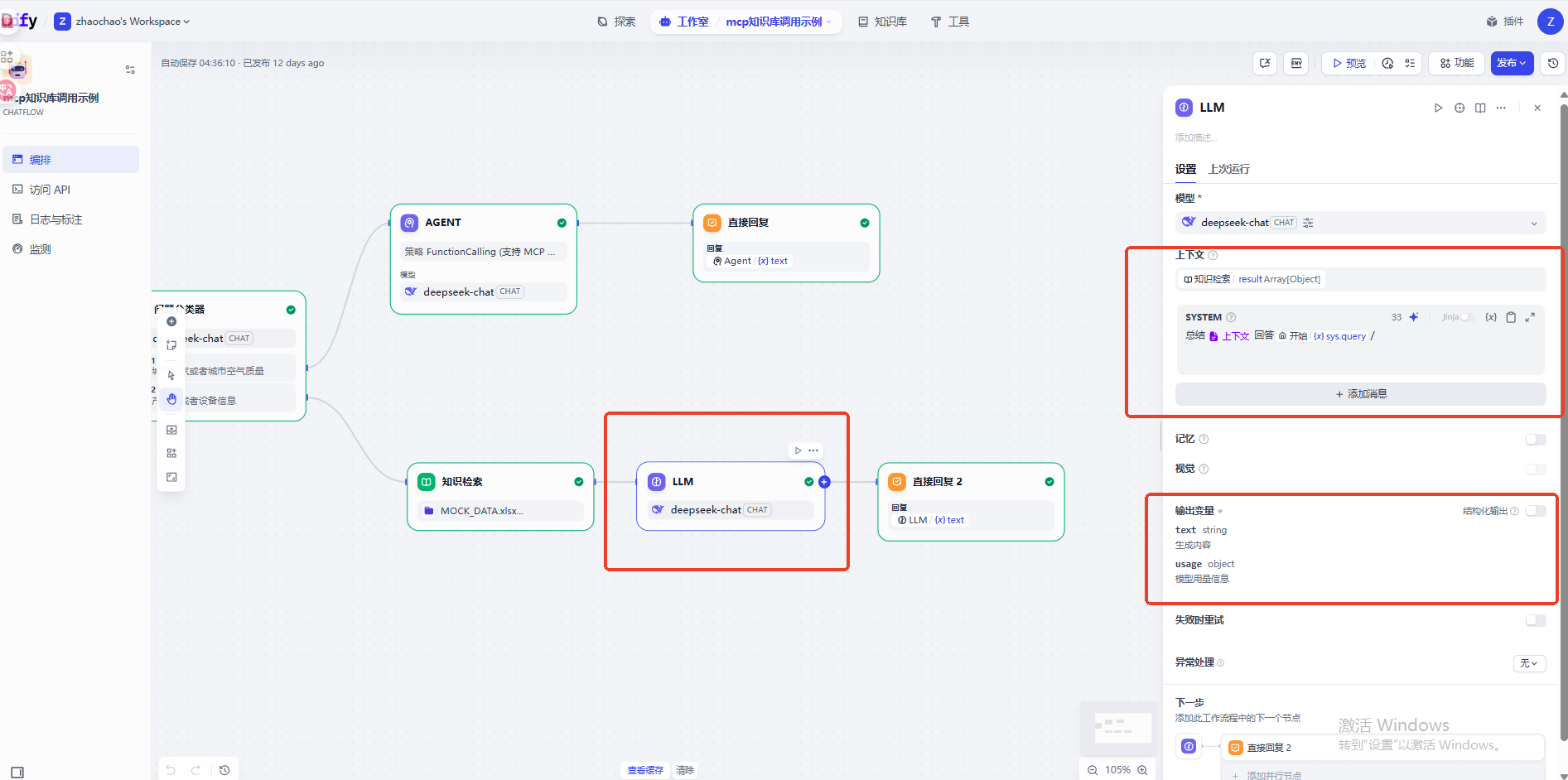
最后直接将模型输出的结果进行返回即可,调用知识库这条线路就已经完成
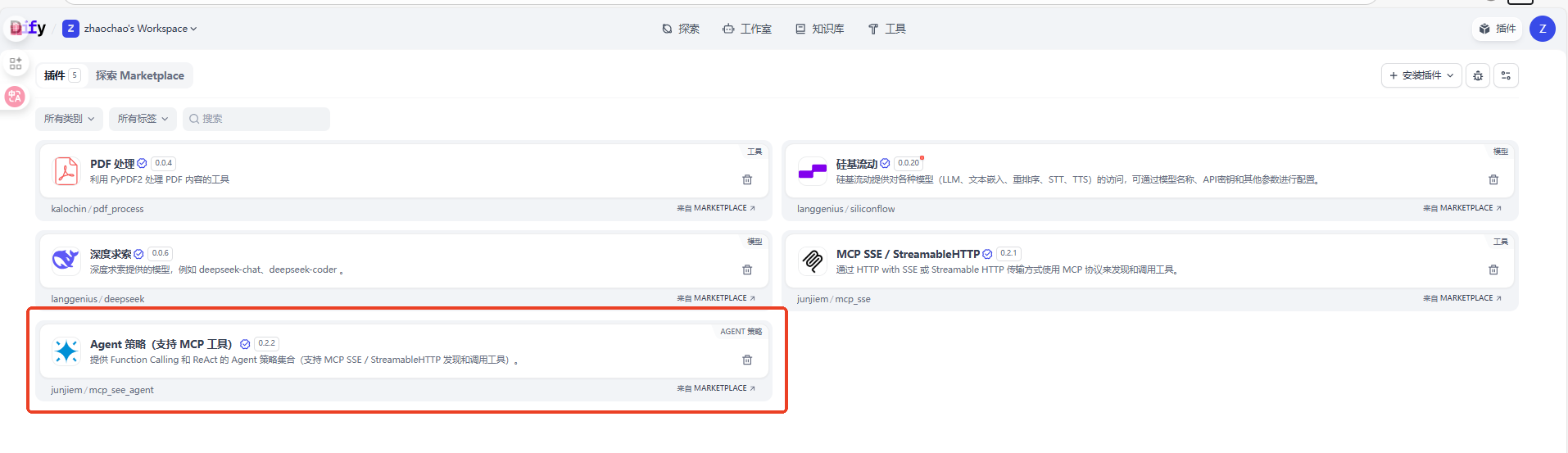
Dify默认不支持MCP调用,但是我们可以添加Agent MCP调用工具,让Agent实现工具调用,点击右上角插件,安装MCP的调用工具。
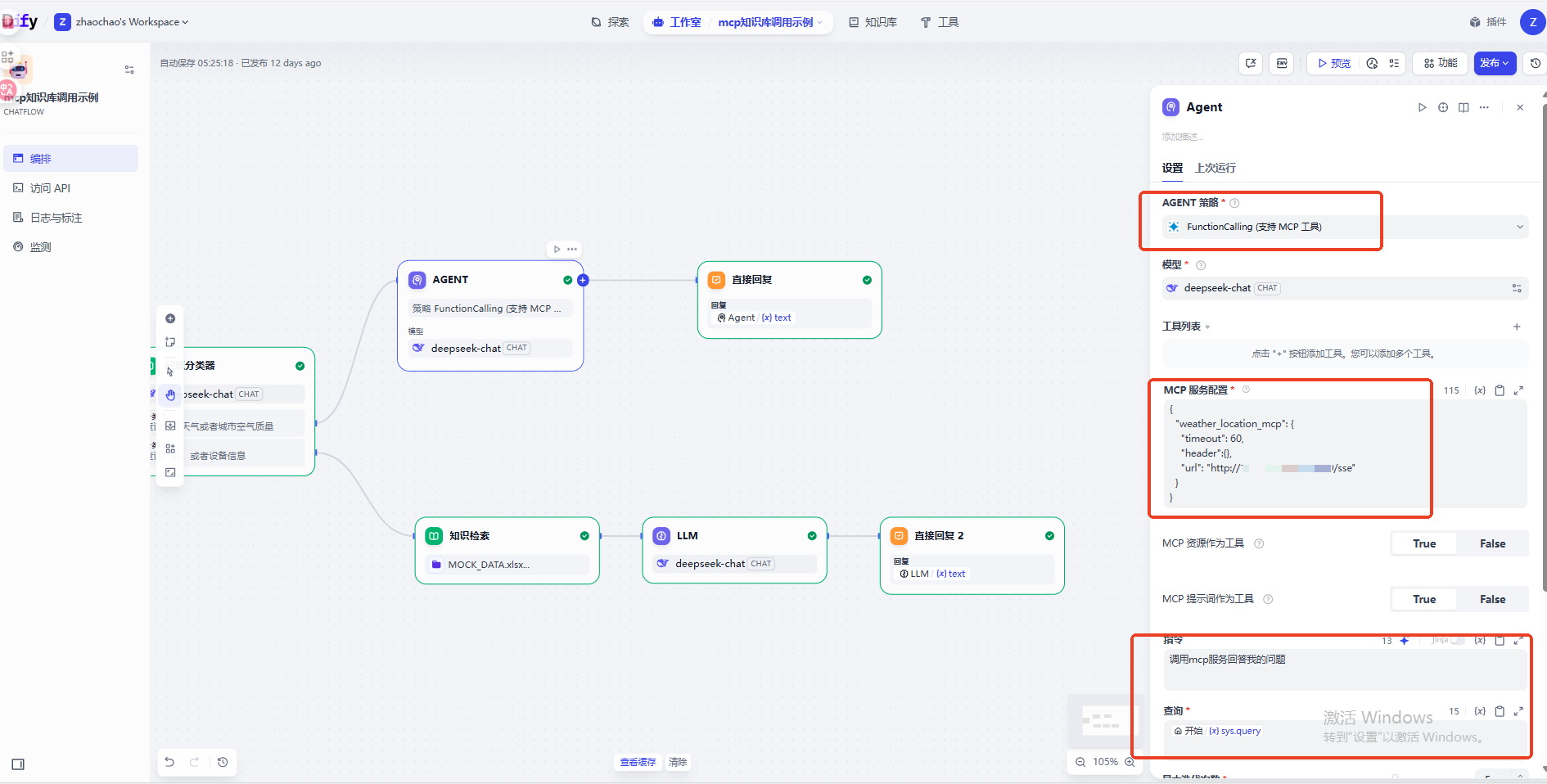
然后创建一个Agent调用MCP能力,配置mcp的地址,查询参数是用户输入的问题,然后模型会自己解析MCP的工具,然后自己调用MCP服务
然后直接将Agent回复的内容回答即可
点击发布运行
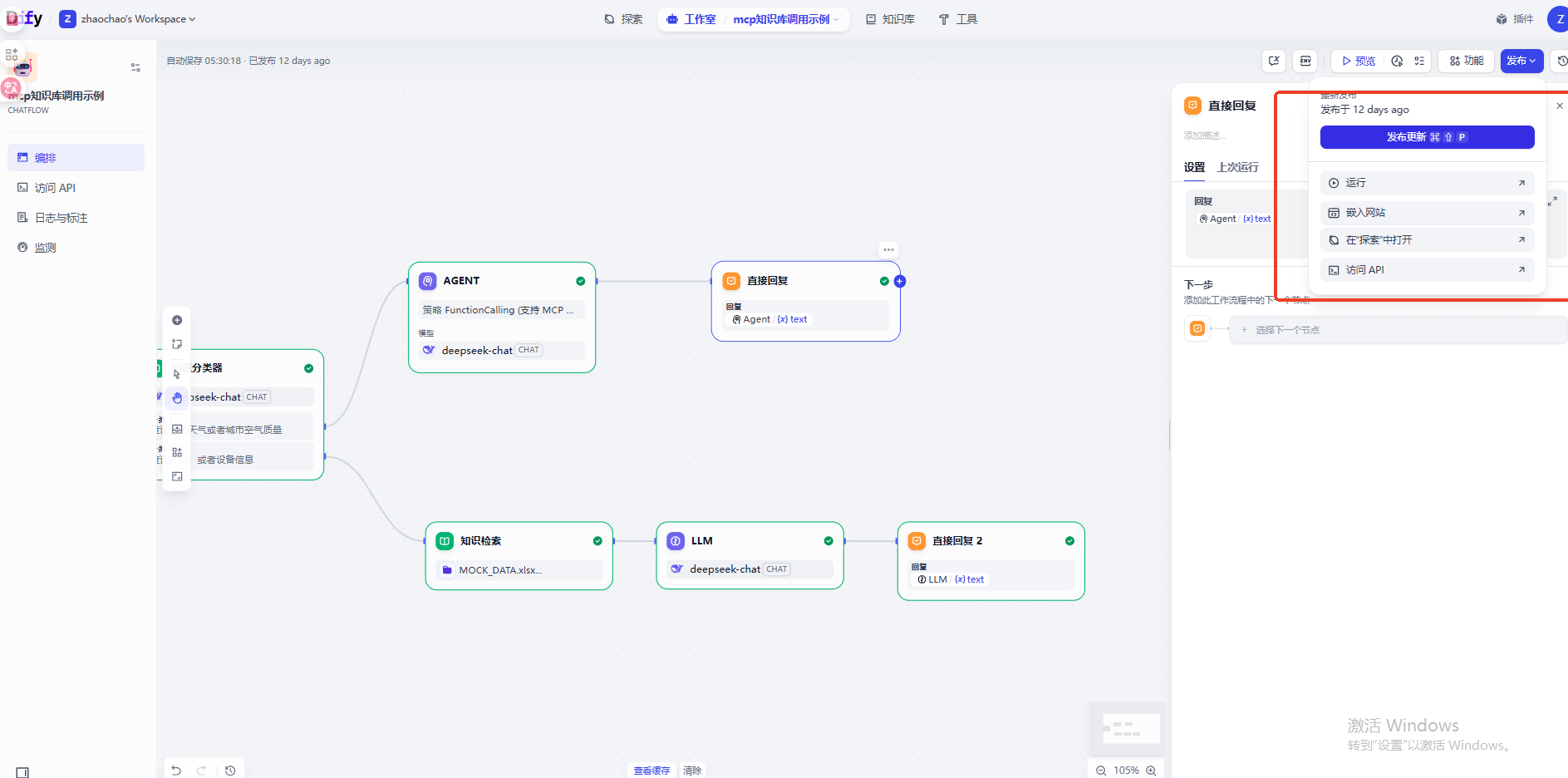
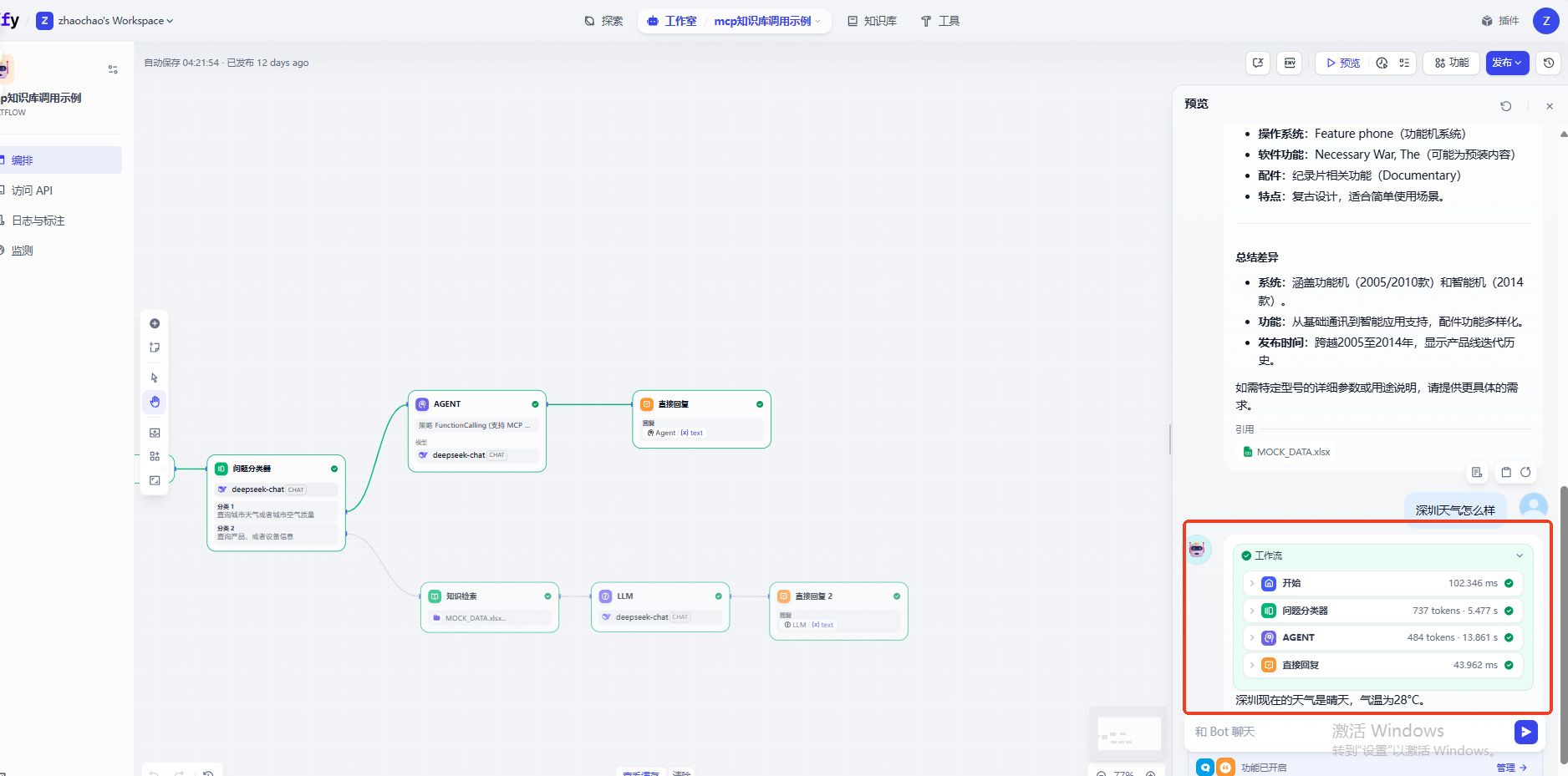
测试知识库查询
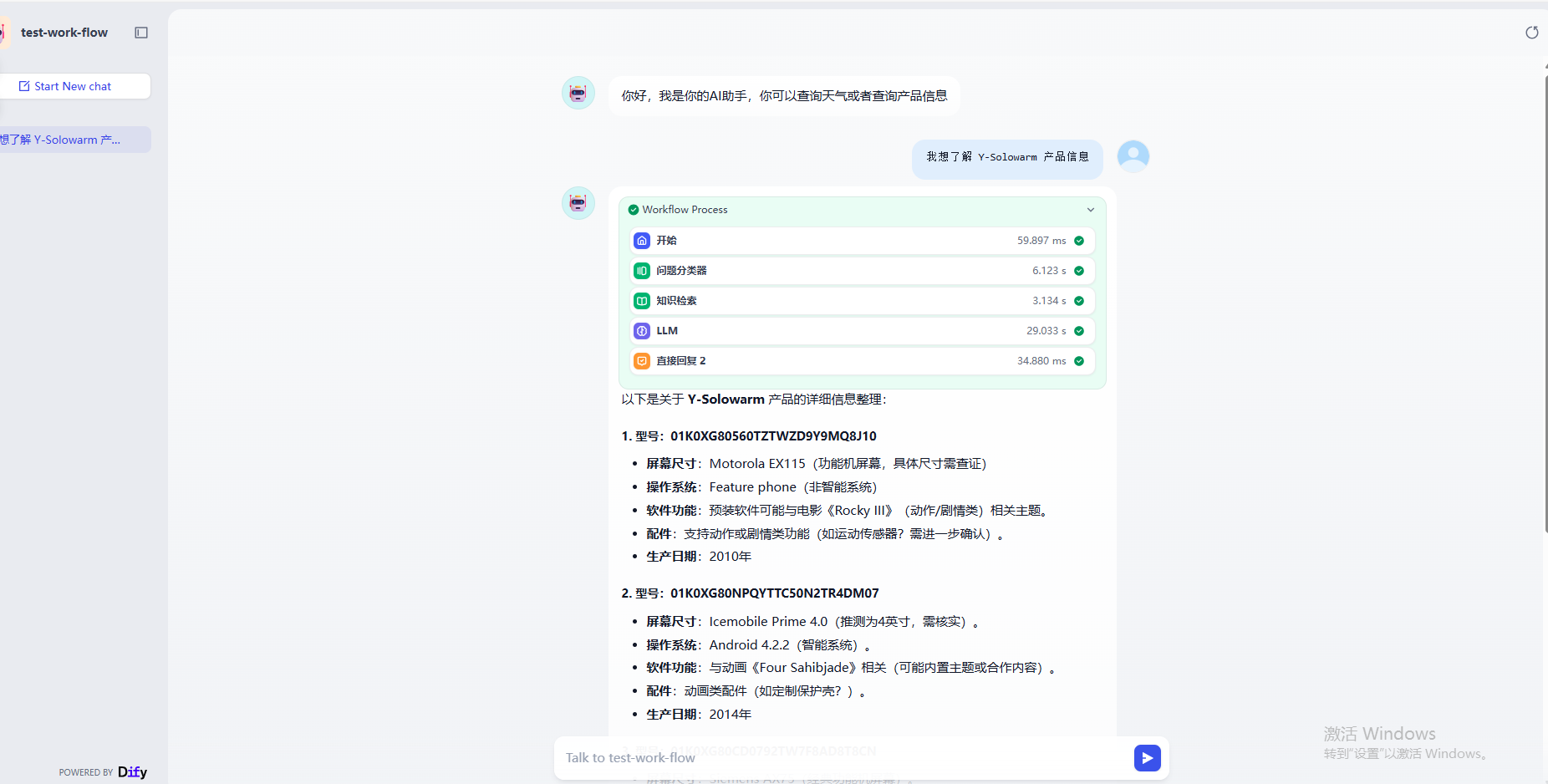
测试MCP,可有看到Agent自动调用了MCP接口并实现了回复